

Sakshi Education
The concept of a file:
File structure is a structure, which is according to a required format that operating system can understand.
Access Methods:
An access method defines the way processes read and write files. We study some of these below.
Structured Files:
So far, we have treated files as byte streams. Database applications often wish to treat them as records, that may be accessed by some key. To accommodate these applications, some systems support typed or structured files that are considered streams of records. If a file is structured, the owner of the file describes the records of the file and the fields to be used as keys. OS/360 for IBM computers and DEC VMS provide such files.
Binding of Access Methods:
An access method may be specified at various times:
Directory Structure:
The structure of the directories and the relationship among them are the main areas where file systems tend to differ, and it is also the area that has the most significant effect on the user interface provided by the file system. The most common directory structures used by multi-user systems are:
File System Mounting:
File Sharing, Protection:
File System Implementation:
File system structure:
File System Implementation:
The Crux: How to Implement a Simple File System
How can we build a simple file system? What structures are needed on the disk? What do they need to track? How are they accessed?
So, a file consists of an inode and the disk blocks that it points to.
Allocation methods:
Contiguous File Allocation:
Linked File Allocation:
Linked File Allocation (cont).
File Allocation Table (FAT).
name
...
start block
Directory entry
217
217
618
618
348
348
end of file
FAT
Indexed File Allocation
A Combined Scheme
Free-space management:
Operating system maintains a list of free disk spaces to keep track of all disk blocks which are not being used by any file. Whenever a file has to be created, the list of free disk space is searched for and then allocated to the new file. The amount of space allocated to this file is then removed from the free space list. When a file is deleted, its disk space is added to the free space list. In this section we will discuss two methods to manage free disk blocks.
Linked List:
In this method all free disk blocks are linked together by each free block pointing to the next free block. There must be another pointer pointing to the first free block of a linked list which will be pointing to the second free block which would further point to the third free block and so on. In the following example (figure 4) block 3 is the first free block of a linked list of free disk blocks which will be pointed to by some.
This scheme is not very efficient since to traverse the list, we must read each block requiring substantial time. The second disadvantage is additional memory requirement for maintaining linked list of all free disk blocks. With a I K block and 16 bit disk block number, each block on the free list holds the numbers of 512 free blocks. A 20M disk needs a free list of maximum 40 blocks to hold all 20,000 disk block numbers.
Bit Map:
Most often the list of free disk spaces is implemented as a bit map or bit vector. Each block is represented by a single bit. 0(zero) is marked as a free block whereas 1 is for allocated block.
For example consider a disk (figure 4) where blocks 3,5,7,9,10,13,15,20 & 28 are free and the rest of the blocks are allocated to a file. The bit map for free disk blocks would he 1 1 1 0 1 0 1 0 1 0 0 1 1 0 1 0 1 1 1 1 0 1 1 1 1 1 1 1 0 1. One advantage of this approach is that it is a simple method and efficient to find n consecutive free blocks on the disk. But the disadvantage is that extra disk space is required to store bit map. A disk with n blocks require a bit map of n bits.
Efficiency and performance:
Lake Partners Strategy Consultants conducted research to understand the efficiencies created by different operating systems. Research included (but was not limited to) investigation of Juniper Network’s operating system (JUNOS software). For customers who perceived a difference in efficiency between operating systems, Lake Partners quantified that difference in key network areas.
Based on these customer interviews and the data collected, Lake Partners’ found that in specific network areas JUNOS software creates significant and meaningful operational efficiencies. Specifically, those who perceive the most impact from JUNOS software save a total of 25% of time on common network operations tasks compared to competitive operating systems.
Methodology
In total 122 network operations team leaders were interviewed and asked a variety of questions regarding daily operations and the hardware currently deployed in their network. Respondent companies ranged in size (mid-sized to enterprise class) and were from a variety of industry verticals (including but not limited to healthcare, finance, telecommunications, government, and education). Data was collected in one of two ways: through a detailed online survey or by phone. One hundred decision makers who had visibility to network operations completed Lake Partners’ survey online via email. An additional twenty two respondents were interviewed in depth over the phone.
As a starting point, Lake Partners created a baseline of how much network operations time was devoted to routers (as opposed to other network infrastructure).
UNIX:
In the previous chapters, we examined many operating system principles, abstractions, algorithms, and techniques in general. Now it is time to look at some concrete systems to see how these principles are applied in the real world. We will begin with UNIX because it runs on a wider variety of computers than any other operating system. It is the dominant operating system on high-end workstations and servers, but it is also used on systems ranging from notebook computers to supercomputers. It was carefully designed with a clear goal in mind.
And despite its age, is still modern and elegant. Many important design principles are illustrated by UNIX. Quite a few of these have been copied by other systems. Our discussion of UNIX will start with its history and evolution of the system. Then we will provide an overview of the system, to give an idea of how it is used. This overview will be of special value to readers familiar only with Windows, since the latter hides virtually all the details of the system from its users. Although graphical interfaces may be easy for beginners, they provide little flexibility and no insight into how the system works.
Next we come to the heart of this chapter, an examination of processes, memory management, I/O, the file system, and security in UNIX. For each topic we will first discuss the fundamental concepts, then the system calls, and finally the implementation. One problem that we will encounter is that there are many versions and clones of UNIX, including AIX, BSD, 1BSD, HP-UX, Linux, MINIX, OSF/1, SCO UNIX, System V, Solaris, XENIX, and various others, and each of these has gone through many versions. Fortunately, the fundamental principles and system calls are pretty much the same for all of them (by design). Furthermore, the general implementation strategies, algorithms, and data structures are similar, but there are some differences. In this chapter we will draw upon several examples when discussing implementation, primarily 4.4BSD (which forms the basis for FreeBSD), System V Release 4, and Linux. Additional information about various implementations can be found in (Beck et al., 1998; Goodheart and Cox, 1994; Maxwell, 1999; McKusick et al., 1996; Pate, 1996; and Vahalia, 1996).
HISTORY OF UNIX:
Unix has a long and interesting history, so we will begin our study there. What started out as the pet project of one young researcher has become a multimillion dollar industry involving Universities, multi-national corporations, governments and international standardization bodies.
LINUX:
During the early years of MINIX development and discussion on the Internet, many people requested (or in many cases, demanded) more and better features, to which the author often said “No” (to keep the system small enough for students to understand completely in a one-semester university course). This continuous “No” irked many users. At this time, FreeBSD was not available, so that was not an option. After a number of years went by like this, a Finnish student, Linus Torvalds, decided to write another UNIX clone, named Linux, which would be a full-blown production system with many features MINIX was (intentionally) lacking. The first version of Linux, 0.01, was released in 1991. It was cross-developed on a MINIX machine and borrowed some ideas from MINIX ranging from the structure of the source tree to the layout of the file system. However, it was a monolithic rather than a microkernel design, with the entire operating system in the kernel. The code size totaled 9,300 lines of C and 950 lines of assembler, roughly similar to MINIX version in size and also roughly comparable in functionality.
Linux rapidly grew in size and evolved into a full production UNIX clone as virtual memory, a more sophisticated file system, and many other features were added. Although it originally ran only on the 386 (and even had embedded 386 assembly code in the middle of C procedures), it was quickly ported to other platforms and now runs on a wide variety of machines, just as UNIX does. One difference with UNIX does stand out however: Linux makes use of many special features of the gcc compiler and would need a lot of work before it would compile with an ANSI standard C compiler with no extra features.
The next major release of Linux was version 1.0, issued in 1994. It was about 165,000 lines of code and included a new file system, memory-mapped files, and BSD-compatible networking with sockets and TCP/IP. It also included many new device drivers. Several minor revisions followed in the next two years.
By this time, Linux was sufficiently compatible with UNIX that a vast amount of UNIX software was ported to Linux, making it far more useful than it would have otherwise been. In addition, a large number of people were attracted to Linux and began working on the code and extending it in many ways under Torvalds’ general supervision.
The next major release, 2.0, was made in 1996. It consisted of about 470,000 lines of C and 8000 lines of assembly code. It included support for 64-bit architectures, symmetric multiprogramming, new networking protocols, and numerous other features. A large fraction of the total code mass was taken up by an extensive collection of device drivers. Additional releases followed frequently.
A large array of standard UNIX software has been ported to Linux, including over 1000 utility programs, X Windows and a great deal of networking software. Two different GUIs (GNOME and KDE) have also been written for Linux. In short, it has grown to a full-blown UNIX clone with all the bells and whistles a UNIX lover might want.
One unusual feature of Linux is its business model: it is free software. It can be downloaded from various sites on the Internet, for example: www.kernel.org. Linux comes with a license devised by Richard Stallman, founder of the Free Software Foundation. Despite the fact that Linux is free, this license, the GPL (GNU Public License), is longer than Microsoft’s Windows 2000 license and specifies what you can and cannot do with the code. Users may use, copy, modify, and redistribute the source and binary code freely. The main restriction is that all works derived from the Linux kernel may not be sold or redistributed in binary form only; the source code must either be shipped with the product or be made available on request.
Although Torvalds still controls the kernel fairly closely, a large amount of user-level software has been written by numerous other programmers, many of them originally migrated over from the MINIX, BSD, and GNU (Free Software Foundation) online communities. However, as Linux evolves, a steadily smaller fraction of the Linux community want to hack source code (witness hundreds of books telling how to install and use Linux and only a handful discussing the code or how it works). Also, many Linux users now forego the free distribution on the Internet to buy one of many CD-ROM distributions available from numerous competing commercial companies. A web site listing over 50 companies that sell different Linux packages is www.linux.org
WINDOWS:
Case Study Of Windows 7 O.S:
Objectives:
Windows 7 :
History:
Design Principles:
Windows Architecture:
File structure is a structure, which is according to a required format that operating system can understand.
- A file has a certain defined structure according to its type.
- A text file is a sequence of characters organized into lines.
- A source file is a sequence of procedures and functions.
- An object file is a sequence of bytes organized into blocks that are understandable by the machine.
- When operating system defines different file structures, it also contains the code to support these file structure. Unix, MS-DOS support minimum number of file structure.
Access Methods:
An access method defines the way processes read and write files. We study some of these below.
- Sequential Access: Under this access method, the entire file is read or written from the beginning to the end sequentially.
- Files in popular programming languages such as Pascal and Ada provide such access. The file is associated with a read/write mark, which is advanced on each access.
- If several processes are reading or writing from the same file, then the system may define one read/ write mark or several. In the former case, the read/write mark is kept at a central place, while in the latter case it is kept with the process table entry.
- In Unix, a combination of the two schemes is provided, as we shall see later.
- Direct Access: This access allows a user to position the read/write mark before reading or writing. This feature is useful for applications such as editors that need to randomly access the contents of the file.
- Mapped Access: The Multics operating systems provide a novel form of access which we shall call mapped access.
- When a process opens a file, it is mapped to a segment. The open call returns the number of this segment.
- The process can thus access the file as part of its virtual store. The CloseSegment call may be used to close the file.
Structured Files:
So far, we have treated files as byte streams. Database applications often wish to treat them as records, that may be accessed by some key. To accommodate these applications, some systems support typed or structured files that are considered streams of records. If a file is structured, the owner of the file describes the records of the file and the fields to be used as keys. OS/360 for IBM computers and DEC VMS provide such files.
Binding of Access Methods:
An access method may be specified at various times:
- When the operating system is designed. In this case, all files use the same method.
- When the file is created. Thus, every time the file is opened, the same access method will be used.
- When the file is opened. Several processes can have the same file open and access it differently.
Directory Structure:
The structure of the directories and the relationship among them are the main areas where file systems tend to differ, and it is also the area that has the most significant effect on the user interface provided by the file system. The most common directory structures used by multi-user systems are:
- Single-level directory
- Two-level directory
- Tree-structured directory
- Single-Level Directory:
- In a single-level directory system, all the files are placed in one directory. This is very common on single-user OS's.
- A single-level directory has significant limitations, however, when the number of files increases or when there is more than one user. Since all files are in the same directory, they must have unique names. If there are two users who call their data file "test", then the unique-name rule is violated.
- Although file names are generally selected to reflect the content of the file, they are often quite limited in length.
- Even with a single-user, as the number of files increases, it becomes difficult to remember the names of all the files in order to create only files with unique names.
- Two-Level Directory:
- In the two-level directory system, the system maintains a master block that has one entry for each user. This master block contains the addresses of the directory of the users.
- There are still problems with two-level directory structure. This structure effectively isolates one user from another. This is an advantage when the users are completely independent, but a disadvantage when the users want to cooperate on some task and access files of other users.
- Some systems simply do not allow local files to be accessed by other users.
- Tree-Structured Directories:
- In the tree-structured directory, the directory themselves are files. This leads to the possibility of having sub-directories that can contain files and sub-subdirectories.
- An interesting policy decision in a tree-structured directory structure is how to handle the deletion of a directory.
- If a directory is empty, its entry in its containing directory can simply be deleted. However, suppose the directory to be deleted id not empty, but contains several files, or possibly sub-directories.
- Some systems will not delete a directory unless it is empty. Thus, to delete a directory, someone must first delete all the files in that directory. If these are any sub-directories.
File System Mounting:
- Mounting file system option allows your workstation to configure what file system can be accessed.
- File systems reside on mass storage devices such as diskettes, hard drives, and CD-ROMs.
- Each storage media can be a different type of file system such as FAT, FAT32, NTFS, and HPFS etc.
- Under Linux, it is possible to link different file systems on a mass storage device into a single, larger file system. This is accomplished by placing mounting points of a device's file system in a directory on another file system.
- So while the root directory of a drive on a different machine may be referred to as c:\, the same drive on a Linux system may be accessible as /mnt/xdir; where xdir can be any name (it is a directory, known as mount point).
- When a device is mounted, it is then accessible to the system's users who have proper permission to access it. Linux conf is a way of mounting file systems.
- You can also mount it by command line. For example, to mount the first diskette drive on /mnt/floppy, you would type the command mount /dev/fd0 /mnt/floppy
- Note that floppy is a subdirectory inside mnt directory.
- During the installation of Linux, a file that holds the information of mount points is created and it is located in /etc/fstab
- To auto mount devices at boot time, this file can be edited to add new devices that points to file systems.
File Sharing, Protection:
- File sharing is the public or private sharing of computer data or space in a network with various levels of access privilege. While files can easily be shared outside a network (for example, simply by handing or mailing someone your file on a diskette), the term file sharing almost always means sharing files in a network, even if in a small local area network.
- File sharing allows a number of people to use the same file or file by some combination of being able to read or view it, write to or modify it, copy it, or print it. Typically, a file sharing system has one or more administrators.
- Users may all have the same or may have different levels of access privilege. File sharing can also mean having an allocated amount of personal file storage in a common file system.
File System Implementation:
- Boot control block contains info needed by system to boot OS from that volume.
- Volume control block contains volume details.
- Directory structure organizes the files.
- Per-file File Control Block (FCB) contains many details about the file.

File system structure:
- File structure consists of Logical storage and Collection of related information.
- File system resides on secondary storage (disks). File system organized into layers. File control block – storage structure consisting of information about a file.
File System Implementation:
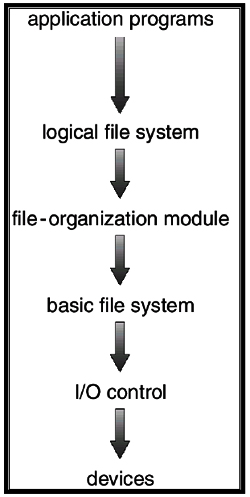
- In this chapter, we introduce a simple file system implementation, known as vsfs (the Very Simple File System). This file system is a simplified version of a typical UNIX file system and thus serves to introduce some of the basic on-disk structures, access methods, and various policies that you will find in many file systems today.
- The file system is pure software; unlike our development of CPU and memory virtualization, we will not be adding hardware features to make some aspect of the file system work better (though we will want to pay attention to device characteristics to make sure the file system works well).
- Because of the great flexibility we have in building a file system, many different ones have been built, literally from AFS (the Andrew File System) [H+88] to ZFS (Sun’s Zettabyte File System) [B07].
- All of these file systems have different data structures and do some things better or worse than their peers. Thus, the way we will be learning about file systems is through case studies: first, a simple file system (vsfs) in this chapter to introduce most concepts, and then a series of studies of real file systems to understand how they can differ in practice.
The Crux: How to Implement a Simple File System
How can we build a simple file system? What structures are needed on the disk? What do they need to track? How are they accessed?
- Directory Implementation: Discuss several file system implementation strategies.
- First implementation strategy: contiguous allocation. Just lay out the file in contiguous disk blocks. Used in VM/CMS - an old IBM interactive system.
Advantages:- Quick and easy calculation of block holding data - just offset from start of file!
- For sequential access, almost no seeks required.
- Even direct access is fast - just seek and read. Only one disk access.
Disadvantages:- Where is best place to put a new file?
- Problems when file gets bigger - may have to move whole file!!
- External Fragmentation.
- Compaction may be required, and it can be very expensive.
- Next strategy: linked allocation. All files stored in fixed size blocks. Link together adjacent blocks like a linked list.
Advantages:- No more variable-sized file allocation problems. Everything takes place in fixed-size chunks, which makes memory allocation a lot easier.
- No more external fragmentation.
- No need to compact or relocate files.
Disadvantages:- Potentially terrible performance for direct access files - have to follow pointers from one disk block to the next!
- Even sequential access is less efficient than for contiguous files because may generate long seeks between blocks.
- Reliability -if lose one pointer, have big problems.
- FAT allocation. Instead of storing next file pointer in each block, have a table of next pointers indexed by disk block. Still have to linearly traverse next pointers, but at least don't have to go to disk for each of them. Can just cache the FAT table and do traverse all in memory. MS/DOS and OS/2 use this scheme.
- Table pointer of last block in file has EOF pointer value. Free blocks have table pointer of 0. Allocation of free blocks with FAT scheme is straightforward. Just search for first block with 0 table pointer.
- Indexed Schemes. Give each file an index table. Each entry of the index points to the disk blocks containing the actual file data. Supports fast direct file access, and not bad for sequential access.
- Question: how to allocate index table? Must be stored on disk like everything else in the file system. Have basically same alternatives as for file itself! Contiguous, linked, and multilevel index. In practice some combination scheme is usually used. This whole discussion is reminiscent of paging discussions.
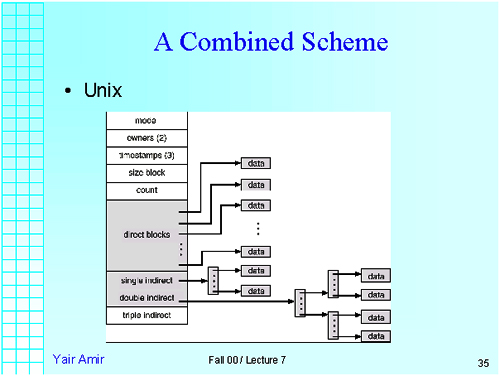
- Will now discuss how traditional Unix lays out file system.
- First 8KB - label + boot block. Next 8KB - Superblock plus free inode and disk block cache.
- Next 64KB - inodes. Each inode corresponds to one file.
- Until end of file system - disk blocks. Each disk block consists of a number of consecutive sectors.
- What is in an inode - information about a file. Each inode corresponds to one file. Important fields:
- Mode. This includes protection information and the file type. File type can be normal file (-), directory (d), symbolic link (l).
- Owner
- Number of links - number of directory entries that point to this inode.
- Length - how many bytes long the file is.
- Nblocks - number of disk blocks the file occupies.
- Array of 10 direct block pointers. These are first 10 blocks of file.
- One indirect block pointer. Points to a block full of pointers to disk blocks.
- One doubly indirect block pointer. Points to a block full of pointers to blocks full of pointers to disk blocks.
- One triply indirect block pointer. (Not currently used).
So, a file consists of an inode and the disk blocks that it points to.
- Nblocks and Length do not contain redundant information - can have holes in files. A hole shows up as block pointers that point to block 0 - i.e., nothing in that block.
- Assume block size is 512 bytes (i.e. one sector). To access any of first 512*10 bytes of file, can just go straight from inode. To access data farther in, must go indirect through at least one level of indirection.
- What does a directory look like? It is a file consisting of a list of (name,inode number) pairs. In early Unix Systems the name was a maximum of 14 characters long, and the inode number was 2 bytes. Later versions of Unix removed this restriction, and each directory entry was variable length and also included the length of the file name.
- Why don't inodes contain names? Because would like a file to be able to have multiple names.
- How does Unix implement the directories . and ..? They are just names in the directory. . points to the inode of the directory, while .. points to the inode of the directory's parent directory. So, there are some circularities in the file system structure.
- User can refer to files in one of two ways: relative to current directory, or relative to the root directory. Where does lookup for root start? By convention, inode number 2 is the inode for the top directory. If a name starts with /, lookup starts at the file for inode number 2.
- How does system convert a name to an inode? There is a routine called namei that does it.
- Do a simple file system example, draw out inodes and disk blocks, etc. Include counts, length, etc.
- What about symbolic links? A symbolic link is a file containing a file name. Whenever a Unix operation has the name of the symbolic link as a component of a file name, it macro substitutes the name in the file in for the component.
Allocation methods:
- Contiguous allocation.
- Linked allocation.
- Indexed allocation.
- Multilevel indexed allocation.
- Combined scheme.
Contiguous File Allocation:
- Each file occupies a set of contiguous blocks on the disk.
- Allocation using first fit / best fit.
- A Need for compaction.
- Only starting block and length of file in blocks are needed to work with the file.
- Allows random access.
- Problems with files that grow.
Linked File Allocation:
- Each file is a linked list of blocks.
- Tradeoffs?
- No external fragmentation.
- Effective for sequential access.
- Problematic for direct access.
Linked File Allocation (cont).
- How it looks on the disk:
File Allocation Table (FAT).
- Variation of the link list (MS/DOS and OS/2).
- A section of the disk at the beginning of each partition (Volume) is set aside to contain a FAT.
- FAT has one entry for each disk block, pointing to the next block in the file.
- The link list is implemented in that section.
- Actual file blocks contain no links.
name
...
start block
Directory entry
217
217
618
618
348
348
end of file
FAT
Indexed File Allocation
- Indexed allocation is bringing all the pointers together.
- Tradeoffs?
- Much more effective for direct access.
- Inefficient for small files
- both access and space.
A Combined Scheme
- Unix
Free-space management:
Operating system maintains a list of free disk spaces to keep track of all disk blocks which are not being used by any file. Whenever a file has to be created, the list of free disk space is searched for and then allocated to the new file. The amount of space allocated to this file is then removed from the free space list. When a file is deleted, its disk space is added to the free space list. In this section we will discuss two methods to manage free disk blocks.
Linked List:
In this method all free disk blocks are linked together by each free block pointing to the next free block. There must be another pointer pointing to the first free block of a linked list which will be pointing to the second free block which would further point to the third free block and so on. In the following example (figure 4) block 3 is the first free block of a linked list of free disk blocks which will be pointed to by some.
This scheme is not very efficient since to traverse the list, we must read each block requiring substantial time. The second disadvantage is additional memory requirement for maintaining linked list of all free disk blocks. With a I K block and 16 bit disk block number, each block on the free list holds the numbers of 512 free blocks. A 20M disk needs a free list of maximum 40 blocks to hold all 20,000 disk block numbers.
Bit Map:
Most often the list of free disk spaces is implemented as a bit map or bit vector. Each block is represented by a single bit. 0(zero) is marked as a free block whereas 1 is for allocated block.
For example consider a disk (figure 4) where blocks 3,5,7,9,10,13,15,20 & 28 are free and the rest of the blocks are allocated to a file. The bit map for free disk blocks would he 1 1 1 0 1 0 1 0 1 0 0 1 1 0 1 0 1 1 1 1 0 1 1 1 1 1 1 1 0 1. One advantage of this approach is that it is a simple method and efficient to find n consecutive free blocks on the disk. But the disadvantage is that extra disk space is required to store bit map. A disk with n blocks require a bit map of n bits.
Efficiency and performance:
Lake Partners Strategy Consultants conducted research to understand the efficiencies created by different operating systems. Research included (but was not limited to) investigation of Juniper Network’s operating system (JUNOS software). For customers who perceived a difference in efficiency between operating systems, Lake Partners quantified that difference in key network areas.
Based on these customer interviews and the data collected, Lake Partners’ found that in specific network areas JUNOS software creates significant and meaningful operational efficiencies. Specifically, those who perceive the most impact from JUNOS software save a total of 25% of time on common network operations tasks compared to competitive operating systems.
Methodology
In total 122 network operations team leaders were interviewed and asked a variety of questions regarding daily operations and the hardware currently deployed in their network. Respondent companies ranged in size (mid-sized to enterprise class) and were from a variety of industry verticals (including but not limited to healthcare, finance, telecommunications, government, and education). Data was collected in one of two ways: through a detailed online survey or by phone. One hundred decision makers who had visibility to network operations completed Lake Partners’ survey online via email. An additional twenty two respondents were interviewed in depth over the phone.
As a starting point, Lake Partners created a baseline of how much network operations time was devoted to routers (as opposed to other network infrastructure).
UNIX:
In the previous chapters, we examined many operating system principles, abstractions, algorithms, and techniques in general. Now it is time to look at some concrete systems to see how these principles are applied in the real world. We will begin with UNIX because it runs on a wider variety of computers than any other operating system. It is the dominant operating system on high-end workstations and servers, but it is also used on systems ranging from notebook computers to supercomputers. It was carefully designed with a clear goal in mind.
And despite its age, is still modern and elegant. Many important design principles are illustrated by UNIX. Quite a few of these have been copied by other systems. Our discussion of UNIX will start with its history and evolution of the system. Then we will provide an overview of the system, to give an idea of how it is used. This overview will be of special value to readers familiar only with Windows, since the latter hides virtually all the details of the system from its users. Although graphical interfaces may be easy for beginners, they provide little flexibility and no insight into how the system works.
Next we come to the heart of this chapter, an examination of processes, memory management, I/O, the file system, and security in UNIX. For each topic we will first discuss the fundamental concepts, then the system calls, and finally the implementation. One problem that we will encounter is that there are many versions and clones of UNIX, including AIX, BSD, 1BSD, HP-UX, Linux, MINIX, OSF/1, SCO UNIX, System V, Solaris, XENIX, and various others, and each of these has gone through many versions. Fortunately, the fundamental principles and system calls are pretty much the same for all of them (by design). Furthermore, the general implementation strategies, algorithms, and data structures are similar, but there are some differences. In this chapter we will draw upon several examples when discussing implementation, primarily 4.4BSD (which forms the basis for FreeBSD), System V Release 4, and Linux. Additional information about various implementations can be found in (Beck et al., 1998; Goodheart and Cox, 1994; Maxwell, 1999; McKusick et al., 1996; Pate, 1996; and Vahalia, 1996).
HISTORY OF UNIX:
Unix has a long and interesting history, so we will begin our study there. What started out as the pet project of one young researcher has become a multimillion dollar industry involving Universities, multi-national corporations, governments and international standardization bodies.
LINUX:
During the early years of MINIX development and discussion on the Internet, many people requested (or in many cases, demanded) more and better features, to which the author often said “No” (to keep the system small enough for students to understand completely in a one-semester university course). This continuous “No” irked many users. At this time, FreeBSD was not available, so that was not an option. After a number of years went by like this, a Finnish student, Linus Torvalds, decided to write another UNIX clone, named Linux, which would be a full-blown production system with many features MINIX was (intentionally) lacking. The first version of Linux, 0.01, was released in 1991. It was cross-developed on a MINIX machine and borrowed some ideas from MINIX ranging from the structure of the source tree to the layout of the file system. However, it was a monolithic rather than a microkernel design, with the entire operating system in the kernel. The code size totaled 9,300 lines of C and 950 lines of assembler, roughly similar to MINIX version in size and also roughly comparable in functionality.
Linux rapidly grew in size and evolved into a full production UNIX clone as virtual memory, a more sophisticated file system, and many other features were added. Although it originally ran only on the 386 (and even had embedded 386 assembly code in the middle of C procedures), it was quickly ported to other platforms and now runs on a wide variety of machines, just as UNIX does. One difference with UNIX does stand out however: Linux makes use of many special features of the gcc compiler and would need a lot of work before it would compile with an ANSI standard C compiler with no extra features.
The next major release of Linux was version 1.0, issued in 1994. It was about 165,000 lines of code and included a new file system, memory-mapped files, and BSD-compatible networking with sockets and TCP/IP. It also included many new device drivers. Several minor revisions followed in the next two years.
By this time, Linux was sufficiently compatible with UNIX that a vast amount of UNIX software was ported to Linux, making it far more useful than it would have otherwise been. In addition, a large number of people were attracted to Linux and began working on the code and extending it in many ways under Torvalds’ general supervision.
The next major release, 2.0, was made in 1996. It consisted of about 470,000 lines of C and 8000 lines of assembly code. It included support for 64-bit architectures, symmetric multiprogramming, new networking protocols, and numerous other features. A large fraction of the total code mass was taken up by an extensive collection of device drivers. Additional releases followed frequently.
A large array of standard UNIX software has been ported to Linux, including over 1000 utility programs, X Windows and a great deal of networking software. Two different GUIs (GNOME and KDE) have also been written for Linux. In short, it has grown to a full-blown UNIX clone with all the bells and whistles a UNIX lover might want.
One unusual feature of Linux is its business model: it is free software. It can be downloaded from various sites on the Internet, for example: www.kernel.org. Linux comes with a license devised by Richard Stallman, founder of the Free Software Foundation. Despite the fact that Linux is free, this license, the GPL (GNU Public License), is longer than Microsoft’s Windows 2000 license and specifies what you can and cannot do with the code. Users may use, copy, modify, and redistribute the source and binary code freely. The main restriction is that all works derived from the Linux kernel may not be sold or redistributed in binary form only; the source code must either be shipped with the product or be made available on request.
Although Torvalds still controls the kernel fairly closely, a large amount of user-level software has been written by numerous other programmers, many of them originally migrated over from the MINIX, BSD, and GNU (Free Software Foundation) online communities. However, as Linux evolves, a steadily smaller fraction of the Linux community want to hack source code (witness hundreds of books telling how to install and use Linux and only a handful discussing the code or how it works). Also, many Linux users now forego the free distribution on the Internet to buy one of many CD-ROM distributions available from numerous competing commercial companies. A web site listing over 50 companies that sell different Linux packages is www.linux.org
WINDOWS:
Case Study Of Windows 7 O.S:
- History
- Design Principles
- System Components
- Environmental Subsystems
- File system
- Networking
- Programmer Interface
Objectives:
- To explore the principles upon which Windows 7 is designed and the specific components involved in the system.
- To understand how Windows 7 can run programs designed for other operating systems.
- To provide a detailed explanation of the Windows 7 file system.
- To illustrate the networking protocols supported in Windows 7.
- To cover the interface available to system and application programmers.
Windows 7 :
- 32-bit/64-bit preemptive multitasking operating system for Intel and AMD microprocessors
- Key goals for the system:
- security
- reliability
- extensibility
- portability
- international support
- energy efficiency
- dynamic device support.
- Supports multiple OS personalities using user-mode subsystems.
- Windows 7 is for desktops. Windows Server 2008 R2 uses the same internals as 64-bit Windows 7, but with added features for servers.
History:
- In 1988, Microsoft decided to develop a “new technology” (NT) portable operating system that supported both the OS/2 and POSIX APIs. NT supported servers as well as desktop workstations.
- Originally, NT was supposed to use the OS/2 API as its native environment but during development NT was changed to use the Win32 API, reflecting the popularity of the Windows 3.0 Win16 API.
- Windows XP was released in 2001 to replace the earlier versions of Windows based on MS/DOS, such as Windows98 and Windows ME.
- Windows XP was updated in 2005 to provide support AMD64 compatible CPUs, bringing support for 64-bit desktop systems.
- Windows Vista was released in late 2006, but was poorly received due to initial problems with application and device compatibility and sluggishness on the explosion of low-end “netbook” devices.
- Windows 7 was released in late 2009, greatly improving on Vista.
- Windows 8 was released in October 2012
- New user interface paradigm (Metro), new type of applications, web store.
Design Principles:
- Extensibility — layered architecture
- Kernel layer runs in protected mode and provides access to the CPU by supporting threads, interrupts, and traps.
- Executive runs in protected mode above the Kernel layer and, provides the basic system services.
- On top of the executive, environmental subsystems operate in user mode providing different OS APIs (as with Mach)
- Modular structure allows additional environmental subsystems to be added without affecting the executive
- Portability —Windows 7 can be moved from one hardware platform to another with relatively few changes
- Written in C and C++
- Platform-dependent code is isolated in a dynamic link library (DLL) called the “hardware abstraction layer” (HAL)
- Reliability —Windows uses hardware protection for virtual memory, and software protection mechanisms for operating system resources.
- Compatibility — applications that follow the IEEE 1003.1 (POSIX) standard can be complied to run on Windows without changing the source code. Applications created for previous versions of Windows run using various virtual machine techniques.
- This is deprecated in Windows 8.
- Performance —Windows subsystems can communicate with one another via high-performance message passing
- Preemption of low priority threads enables the system to respond quickly to external events.
- Designed for symmetrical multiprocessing, scaling to 100s of cores
- International support — supports different locales via the national language support (NLS) API, use of UNICODE throughout, and providing facilities for differences in date formats, currency, etc.
Windows Architecture:
- Layered system of modules
- Protected mode — hardware abstraction layer ( HAL ) , kernel, executive.
- Executive includes file systems, network stack, and device drivers.
- User mode — collection of subsystems, services, DLLs, and the GUI
- Environmental subsystems emulate different operating systems
- Protection subsystems provide security functions
- Windows services provide facilities for networking, device interfaces, background execution, and extension of the system
- Rich shared libraries with thousands of APIs are implemented using DLLs to allow code sharing and simplify updates
- A graphical user interface is built into Win32 and used by most programs that interact directly with the user.
Published date : 16 Feb 2016 02:21PM



