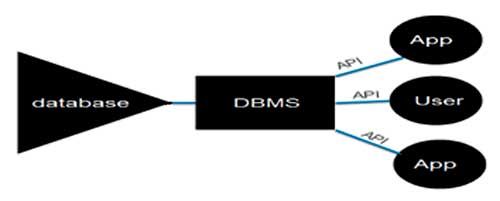
Data base management system is essentially a collection of interrelated data and a set of programs to access this data. This collection of data is called the database. The primary objective of a DBMS is to provide a convenient environment to retrieve and store database information. Database system support single user and multi-user environment. While on one hand DBMS permits only one person to access the database at given time, on the other DBMS allows many users simultaneous access to the database.
A DBMS makes it possible for end users to create, read, update and delete data in a database. The DBMS essentially serves as an interface between the database and end users or application programs, ensuring that data is consistently organized and remains easily accessible.
The DBMS manages three important things: the data, the database engine that allows data to be accessed, locked and modified -- and the database schema, which defines the database’s logical structure. These three foundational elements help provide concurrency, security, data integrity and uniform administration procedures. Typical database administration tasks supported by the DBMS include change management, performance monitoring/tuning and backup and recovery. Many database management systems are also responsible for automated rollbacks, restarts and recovery as well as the logging and auditing of activity.
The DBMS is perhaps most useful for providing a centralized view of data that can be accessed by multiple users, from multiple locations, in a controlled manner. A DBMS can limit what data the end user sees, as well as how that end user can view the data, providing many views of a single database schema. End users and software programs are free from having to understand where the data is physically located or on what type of storage media it resides because the DBMS handles all requests.
The DBMS can offer both logical and physical data independence. That means it can protect users and applications from needing to know where data is stored or having to be concerned about changes to the physical structure of data (storage and hardware). As long as programs use the Application-Programming Interface (API) for the database that is provided by the DBMS, developers won't have to modify programs just because changes have been made to the database.
With relational DBMSs (RDBMSs), this API is SQL, a standard programming language for defining, protecting and accessing data in a RDBMS.
A database system consists of two parts namely, database management system and database applications. Database management system is the program that organizes and maintains the information whereas the database application is the program that let us view, retrieve update information stored in the DBMS.
Database Modes:
Database models are broadly classified into two categories. They are
- Network Model and Hierarchical Model
- Relational Model
- Object based logical Model
- Record based logical model
Access techniques of a DBMS:
The object based logical model can be defined as a collection of ideal tool for describing data, data relationship and data constrains. The record based model describes the data structures access techniques of a DBMS. There are four types of record-based logical models. They are
- File Management System (FMS)
- Hierarchical database management systems (HDBMS)
- Network Database Management Systems (NDBMS)
- Relational Database Management Systems (RDBMS)
Advantages of DBMS
The database management system has promising potential advantages, which are explained below:
- Controlling Redundancy: In file system, each application has its own private files, which cannot be shared between multiple applications. This can often lead to considerable redundancy in the stored data, which results in wastage of storage space. By having centralized database most of this can be avoided. It is not possible that all redundancy should be eliminated. Sometimes there are sound business and technical reasons for• maintaining multiple copies of the same data. In a database system, however this redundancy can be controlled.
For example: In case of college database, there may be the number of applications like General Office, Library, Account Office, Hostel etc. Each of these applications may maintain the following information into own private file applications:
It is clear from the above file systems, that there is some common data of the student which has to be mentioned in each application, like Rollno, Name, Class, Phone_No~ Address etc. This will cause the problem of redundancy which results in wastage of storage space and difficult to maintain, but in case of centralized database, data can be shared by number of applications and the whole college can maintain its computerized data with the following database: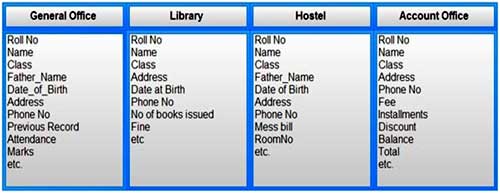
It is clear in the above database that Rollno, Name, Class, Father_Name, Address,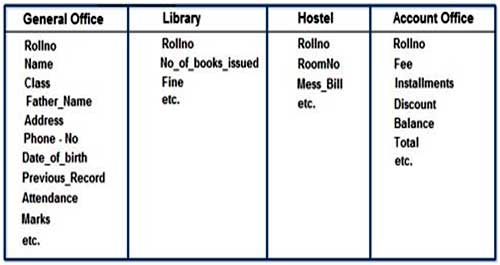
Phone_No, Date_of_birth which are stored repeatedly in file system in each application, need not be stored repeatedly in case of database, because every other application can access this information by joining of relations on the basis of common column i.e. Rollno. Suppose any user of Library system need the Name, Address of any particular student and by joining of Library and General Office relations on the basis of column Rollno he/she can easily retrieve this information.
Thus, we can say that centralized system of DBMS reduces the redundancy of data to great extent but cannot eliminate the redundancy because RollNo is still repeated in all the relations.
- Integrity can be enforced: Integrity of data means that data in database is always accurate, such that incorrect information cannot be stored in database. In order to maintain the integrity of data, some integrity constraints are enforced on the database. A DBMS should provide capabilities for defining and enforcing the constraints.
For Example: Let us consider the case of college database and suppose that college having only BTech, MTech, MSc, BCA, BBA and BCOM classes. But if a \.,ser enters the class MCA, then this incorrect information must not be stored in database and must be prompted that this is an invalid data entry. In order to enforce this, the integrity constraint must be applied to the class attribute of the student entity. But, in case of file system tins constraint must be enforced on all the application separately (because all applications have a class field).
In case of DBMS, this integrity constraint is applied only once on the class field of the General Office (because class field appears only once in the whole database), and all other applications will get the class information about the student from the General Office table so the integrity constraint is applied to the whole database. So, we can conclude that integrity constraint can be easily enforced in centralized DBMS system as compared to file system.
- Inconsistency can be avoided: When the same data is duplicated and changes are made at one site, which is not propagated to the other site, it gives rise to inconsistency and the two entries regarding the same data will not agree. At such times the data is said to be inconsistent. So, if the redundancy is removed chances of having inconsistent data is also removed.
Let us again, consider the college system and suppose that in case of General_Office file
it is indicated that Roll_Number 5 lives in Amritsar but in library file it is indicated that
Roll_Number 5 lives in Jalandhar. Then, this is a state at which tIle two entries of the same object do not agree with each other (that is one is updated and other is not). At such time the database is said to be inconsistent.
An inconsistent database is capable of supplying incorrect or conflicting information. So there should be no inconsistency in database. It can be clearly shown that inconsistency can be avoided in centralized system very well as compared to file system ..
Let us consider again, the example of college system and suppose that RollNo 5 is .shifted from Amritsar to Jalandhar, then address information of Roll Number 5 must be updated, whenever Roll number and address occurs in the system. In case of file system, the information must be updated separately in each application, but if we make updation only at three places and forget to make updation at fourth application, then the whole system show the inconsistent results about Roll Number 5.
In case of DBMS, Roll number and address occurs together only single time in General_Office table. So, it needs single updation and then another application retrieve the address information from General_Office which is updated so, all application will get the current and latest information by providing single update operation and this single update operation is propagated to the whole database or all other application automatically, this property is called as Propagation of Update.
We can say the redundancy of data greatly affect the consistency of data. If redundancy is less, it is easy to implement consistency of data. Thus, DBMS system can avoid inconsistency to great extent.
- Data can be shared: As explained earlier, the data about Name, Class, Father __name etc. of General_Office is shared by multiple applications in centralized DBMS as compared to file system so now applications can be developed to operate against the same stored data. The applications may be developed without having to create any new stored files.
- Standards can be enforced: Since DBMS is a central system, so standard can be enforced easily may be at Company level, Department level, National level or International level. The standardized data is very helpful during migration or interchanging of data. The file system is an independent system so standard cannot be easily enforced on multiple independent applications.
- Restricting unauthorized access: When multiple users share a database, it is likely that some users will not be authorized to access all information in the database. For example, account office data is often considered confidential, and hence only authorized persons are allowed to access such data. In addition, some users may be permitted only to retrieve data, whereas other are allowed both to retrieve and to update. Hence, the type of access operation retrieval or update must also be controlled. Typically, users or user groups are given account numbers protected by passwords, which they can use to gain access to the database. A DBMS should provide a security and authorization subsystem, which the DBA uses to create accounts and to specify account restrictions. The DBMS should then enforce these restrictions automatically.
- Solving Enterprise Requirement than Individual Requirement: Since many types of users with varying level of technical knowledge use a database, a DBMS should provide a variety of user interface. The overall requirements of the enterprise are more important than the individual user requirements. So, the DBA can structure the database system to provide an overall service that is "best for the enterprise".
For example: A representation can be chosen for the data in storage that gives fast access for the most important application at the cost of poor performance in some other application. But, the file system favors the individual requirements than the enterprise requirements
- Providing Backup and Recovery: A DBMS must provide facilities for recovering from hardware or software failures. The backup and recovery subsystem of the DBMS is responsible for recovery. For example, if the computer system fails in the middle of a complex update program, the recovery subsystem is responsible for making sure that the .database is restored to the state it was in before the program started executing.
- Cost of developing and maintaining system is lower: It is much easier to respond to unanticipated requests when data is centralized in a database than when it is stored in a conventional file system. Although the initial cost of setting up of a database can be large, but the cost of developing and maintaining application programs to be far lower than for similar service using conventional systems. The productivity of programmers can be higher in using non-procedural languages that have been developed with DBMS than using procedural languages.
- Data Model can be developed: The centralized system is able to represent the complex data and interfile relationships, which results better data modeling properties. The data madding properties of relational model is based on Entity and their Relationship, which is discussed in detail in chapter 4 of the book.
Concurrency Control: DBMS systems provide mechanisms to provide concurrent access of data to multiple users.
Disadvantages of DBMS
The disadvantages of the database approach are summarized as follows:
- Complexity: The provision of the functionality that is expected of a good DBMS makes the DBMS an extremely complex piece of software. Database designers, developers, database administrators and end-users must understand this functionality to take full advantage of it. Failure to understand the system can lead to bad design decisions, which can have serious consequences for an organization.
- Size: The complexity and breadth of functionality makes the DBMS an extremely large piece of software, occupying many megabytes of disk space and requiring substantial amounts of memory to run efficiently.
- Performance: Typically, a File Based system is written for a specific application, such as invoicing. As result, performance is generally very good. However, the DBMS is written to be more general, to cater for many applications rather than just one. The effect is that some applications may not run as fast as they used to.
- Higher impact of a failure: The centralization of resources increases the vulnerability of the system. Since all users and applications rely on the ~vailabi1ity of the DBMS, the failure of any component can bring operations to a halt.
- Cost of DBMS: The cost of DBMS varies significantly, depending on the environment and functionality provided. There is also the recurrent annual maintenance cost.
- Additional Hardware costs: The disk storage requirements for the DBMS and the database may necessitate the purchase of additional storage space. Furthermore, to achieve the required performance it may be necessary to purchase a larger machine, perhaps even a machine dedicated to running the DBMS. The procurement of additional hardware results in further expenditure.
- Cost of Conversion: In some situations, the cost oftlle DBMS and extra hardware may be insignificant compared with the cost of converting existing applications to run on the new DBMS and hardware. This cost also includes the cost of training staff to use these new systems and possibly the employment of specialist staff to help with conversion and running of the system. This cost is one of the main reasons why some organizations feel tied to their current systems and cannot switch to modern database technology.
Database Management System Vs File Management System
A Database Management System (DMS) is a combination of computer software, hardware, and information designed to electronically manipulate data via computer processing. Two types of database management systems are DBMS’s and FMS’s. In simple terms, a File Management System (FMS) is a Database Management System that allows access to single files or tables at a time. FMS’s accommodate flat files that have no relation to other files. The FMS was the predecessor for the Database Management System (DBMS), which allows access to multiple files or tables at a time (see Figure 1 below)
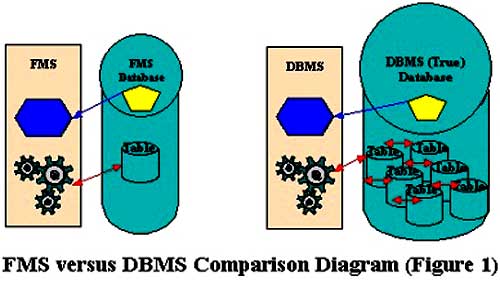
File Management Systems
| Advantages | Disadvantages |
| Simpler to use | Typically does not support multi-user access |
| Less expensive· | Limited to smaller databases |
| Fits the needs of many small businesses and home users | Limited functionality (i.e. no support for complicated transactions, recovery, etc.) |
| Popular FMS’s are packaged along with the operating systems of personal computers (i.e. Microsoft Cardfile and Microsoft Works) | Decentralization of data |
| Good for database solutions for hand held devices such as Palm Pilot | Redundancy and Integrity issues |
Typically, File Management Systems provide the following advantages and disadvantages:
The goals of a File Management System can be summarized as follows (Calleri, 2001):
- Data Management. An FMS should provide data management services to the application.
- Generality with respect to storage devices. The FMS data abstractions and access methods should remain unchanged irrespective of the devices involved in data storage.
- Validity. An FMS should guarantee that at any given moment the stored data reflect the operations performed on them.
- Protection. Illegal or potentially dangerous operations on the data should be controlled by the FMS.
- Concurrency. In multiprogramming systems, concurrent access to the data should be allowed with minimal differences.
- Performance. Compromise data access speed and data transfer rate with functionality.
From the point of view of an end user (or application) an FMS typically provides the following functionalities (Calleri, 2001):
- File creation, modification and deletion.
- Ownership of files and access control on the basis of ownership permissions.
- Facilities to structure data within files (predefined record formats, etc).
- Facilities for maintaining data redundancies against technical failure (back-ups, disk mirroring, etc.).
- Logical identification and structuring of the data, via file names and hierarchical directory structures.
Database Management Systems
Database Management Systems provide the following advantages and disadvantages:
| Advantages | Disadvantages |
| Greater flexibility | Difficult to learn |
| Good for larger databases | Packaged separately from the operating system (i.e. Oracle, Microsoft Access, Lotus/IBM Approach, Borland Paradox, Claris FileMaker Pro) |
| Greater processing power | Slower processing speeds |
| Fits the needs of many medium to large-sized organizations | Requires skilled administrators |
| Storage for all relevant data | Expensive |
| Provides user views relevant to tasks performed | |
| Ensures data integrity by managing transactions (ACID test = atomicity, consistency, isolation, durability) | |
| Supports simultaneous access | |
| Enforces design criteria in relation to data format and structure | |
| Provides backup and recovery controls | |
| Advanced security |
The goals of a Database Management System can be summarized as follows (Connelly, Begg, and Strachan, 1999, pps. 54 – 60):
- Data storage, retrieval, and update (while hiding the internal physical implementation details)
- A user-accessible catalog
- Transaction support
- Concurrency control services (multi-user update functionality)
- Recovery services (damaged database must be returned to a consistent state)
- Authorization services (security)
- Support for data communication Integrity services (i.e. constraints)
- Services to promote data independence
- Utility services (i.e. importing, monitoring, performance, record deletion, etc.)
The components to facilitate the goals of a DBMS may include the following:
- Query processor
- Data Manipulation Language preprocessor
- Database manager (software components to include authorization control, command processor, integrity checker, query optimizer, transaction manager, scheduler, recovery manager, and buffer manager)
- Data Definition Language compiler
- File manager
View of Data:
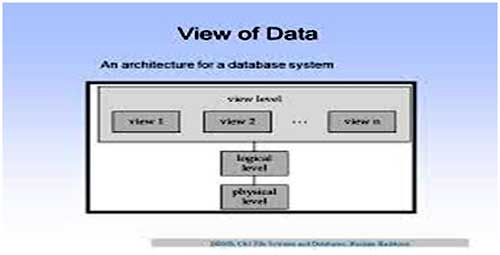
Data are actually stored as bits, or numbers and strings, but it is difficult to work with data at this level. It is necessary to view data at different levels of abstraction.
Schema: Description of data at some level. Each level has its own schema. We will be concerned with three forms of schemas:
- Physical
- Conceptual
- External
Physical Data Level
The physical schema describes details of how data is stored: files, indices, etc. on the random access disk system. It also typically describes the record layout of files and type of files (hash, b-tree, flat).
Early applications worked at this level - explicitly dealt with details. E.g., minimizing physical distances between related data and organizing the data structures within the file (blocked records, linked lists of blocks, etc.)
Problem:
- Routines are hardcoded to deal with physical representation.
- Changes to data structures are difficult to make.
- Application code becomes complex since it must deal with details.
- Rapid implementation of new features very difficult.
Conceptual Data Level
Also referred to as the Logical level
Hides details of the physical level.
- In the relational model, the conceptual schema presents data as a set of tables.
The DBMS maps data access between the conceptual to physical schemas automatically. - Physical schema can be changed without changing application:
- DBMS must change mapping from conceptual to physical.
- Referred to as physical data independence.
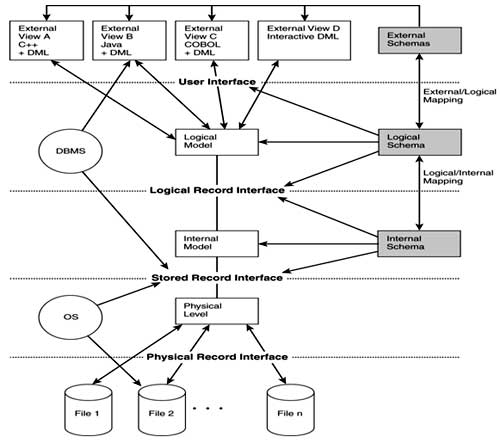
External Data Level
In the relational model, the external schema also presents data as a set of relations. An external schema specifies a view of the data in terms of the conceptual level. It is tailored to the needs of a particular category of users. Portions of stored data should not be seen by some users and begins to implement a level of security and simplifies the view for these users
Examples:
- Students should not see faculty salaries.
- Faculty should not see billing or payment data. Information that can be derived from stored data might be viewed as if it were stored.
- GPA not stored, calculated when needed.
Applications are written in terms of an external schema. The external view is computed when accessed. It is not stored. Different external schemas can be provided to different categories of users. Translation from external level to conceptual level is done automatically by DBMS at run time. The conceptual schema can be changed without changing application:
- Mapping from external to conceptual must be changed.
- Referred to as conceptual data independence.
Instance and schema in DBMS
Definition of schema: Design of a database is called the schema. Schema is of three types: Physical schema, logical schema and view schema.
- The design of a database at physical level is called physical schema, how the data stored in blocks of storage is described at this level.
- Design of database at logical level is called logical schema, programmers and database administrators work at this level, at this level data can be described as certain types of data records gets stored in data structures, however the internal details such as implementation of data structure is hidden at this level (available at physical level).
- Design of database at view level is called view schema. This generally describes end user interaction with database systems. To learn more about these schemas, refer 3 level data abstraction architecture.
Definition of instance:
- The data stored in database at a particular moment of time is called instance of database. Database schema defines the variable declarations in tables that belong to a particular database; the value of these variables at a moment of time is called the instance of that database.
- Independent from the database model it is important to differentiate between the description of the database and the database itself. The description of the database is called database scheme or also metadata. The database scheme is defined during the database design process and changes very rarely afterwards.
- The actual content of the database, the data, changes often over the years. A database state at a specific time defined through the currently existing content and relationship and their attributes is called a database instance.
- The following illustration shows that a database scheme could be looked at like a template or building plan for one or several database instances.
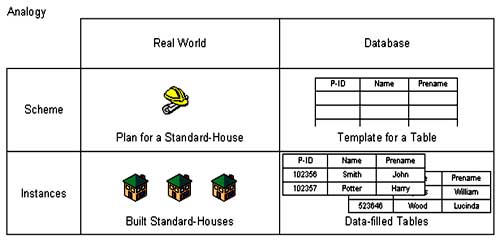
- When designing a database it is differentiated between two levels of abstraction and their respective data schemes, the conceptual and the logical data scheme.
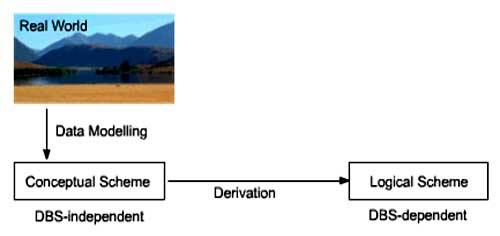
Conceptual Data Scheme: A conceptual data scheme is a system independent data description. That means that it is independent from the database or computer systems used. (Translated) (ZEHNDER 1998)
Logical Data Scheme:
- A logical data scheme describes the data in a data definition language DDL of a specific database management system.
- A logical data scheme describes the data in a data definition language DDL of a specific database management system.
- The conceptual data scheme orients itself exclusively by the database application and therefore by the real world. It does not consider any data technical infrastructure like DBMS or computer systems, which are eventually employed.
- Entity relationship diagrams and relations are tools for the development of a conceptual scheme.
- When designing a database the conceptual data scheme is derived from the logical data scheme (see unit Relational Database Design). This derivation results in a logical data scheme for one specific application and one specific DBMS. A DB-Development System converts then the logical scheme directly into instructions for the DBMS.
Data Models:
- Data models define how the logical structure of a database is modeled. Data Models are fundamental entities to introduce abstraction in a DBMS. Data models define how data is connected to each other and how they are processed and stored inside the system.
- The very first data model could be flat data-models, where all the data used are to be kept in the same plane. Earlier data models were not so scientific, hence they were prone to introduce lots of duplication and update anomalies.
Entity-Relationship Model
- Entity-Relationship (ER) Model is based on the notion of real-world entities and relationships among them. While formulating real-world scenario into the database model, the ER Model creates entity set, relationship set, general attributes and constraints.
- ER Model is best used for the conceptual design of a database.
- ER Model is based on -
- Entities and their attributes.
- Relationships among entities.
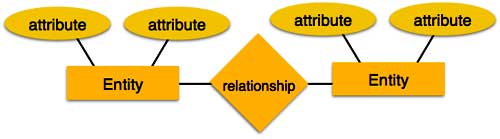
Entity Concept
- Entity - An entity in an ER Model is a real-world entity having properties called attributes. Every attribute is defined by its set of values called domain. For example, in a school database, a student is considered as an entity. Student has various attributes like name, age, class, etc.
- Relationship - The logical association among entities is called relationship. Relationships are mapped with entities in various ways. Mapping cardinalities define the number of association between two entities. Mapping cardinalities are-
- one to one
- one to many
- many to one
- many to many
Entity Relational Components:
- Rectangle: Entity Sets
- Ellipse : Attributes
- Diamond : Relationship sets
- Double Eclipse : Multivalved Attributes
- Dashed Ellipse : Derived Attributes
- Double Rectangle : Weak entity sets
- Lines : Connectors
Relational Model
The most popular data model in DBMS is the Relational Model. It is more scientific a model than others. This model is based on first-order predicate logic and defines a table as an n-ary relation.
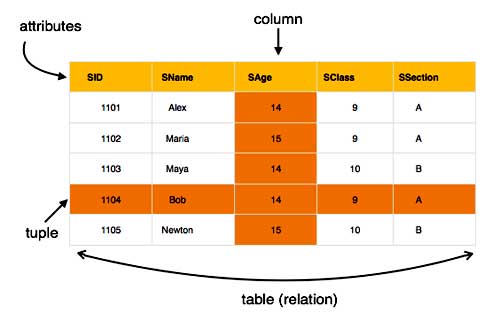
The main highlights of this model are -
- Data is stored in tables called relations.
- Relations can be normalized.
- In normalized relations, values saved are atomic values.
- Each row in a relation contains a unique value.
- Each column in a relation contains values from a same domain.
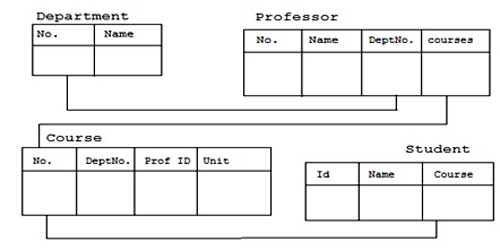
Example: