

Sakshi Education
Introduction:
A compiler translates the code written in one language to some other language without changing the meaning of the program. It is also expected that a compiler should make the target code efficient and optimized in terms of time and space. Compiler design principles provide an in-depth view of translation and optimization process. Compiler design covers basic translation mechanism and error detection & recovery. It includes lexical, syntax, and semantic analysis as front end, and code generation and optimization as back-end.
Phases of Compiler
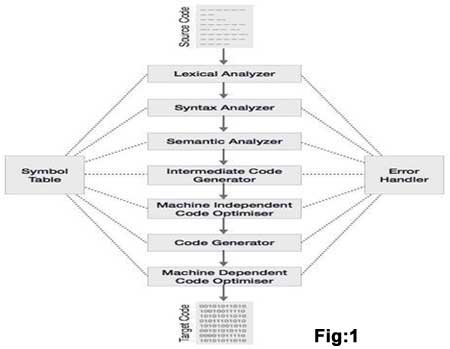
The compilation process is a sequence of various phases. Each phase takes input from its previous stage, has its own representation of source program, and feeds its output to the next phase of the compiler. Let us understand the phases of a compiler. Please refer the below fig. 1
Lexical Analysis
The first phase of scanner works as a text scanner. This phase scans the source code as a stream of characters and converts it into meaningful lexemes. Lexical analyzer represents these lexemes in the form of tokens as:
<token-name, attribute-value>
Syntax Analysis
The next phase is called the syntax analysis or parsing. It takes the token produced by lexical analysis as input and generates a parse tree (or syntax tree). In this phase, token arrangements are checked against the source code grammar, i.e. the parser checks if the expression made by the tokens is syntactically correct.
Semantic Analysis
Semantic analysis checks whether the parse tree constructed follows the rules of language. For example, assignment of values is between compatible data types, and adding string to an integer. Also, the semantic analyzer keeps track of identifiers, their types and expressions; whether identifiers are declared before use or not etc. The semantic analyzer produces an annotated syntax tree as an output.
Intermediate Code Generation
After semantic analysis the compiler generates an intermediate code of the source code for the target machine. It represents a program for some abstract machine. It is in between the high-level language and the machine language. This intermediate code should be generated in such a way that it makes it easier to be translated into the target machine code.
Code Optimization
The next phase does code optimization of the intermediate code. Optimization can be assumed as something that removes unnecessary code lines, and arranges the sequence of statements in order to speed up the program execution without wasting resources (CPU, memory).
Code Generation
In this phase, the code generator takes the optimized representation of the intermediate code and maps it to the target machine language. The code generator translates the intermediate code into a sequence of (generally) re-locatable machine code. Sequence of instructions of machine code performs the task as the intermediate code would do.
Symbol Table
It is a data-structure maintained throughout all the phases of a compiler. All the identifier's names along with their types are stored here. The symbol table makes it easier for the compiler to quickly search the identifier record and retrieve it. The symbol table is also used for scope management.
Pass and Phases of translation:
Bootstrapping
The idea behind bootstrapping is to write a compiler for a language in a possibly older version or a restricted subset of the language. A "quick and dirty" compiler is then written for that language that runs on some machine, but in a restricted subset or older version.
This new version of the compiler incorporates the latest features of the language and generates highly efficient code, and all changes to the language are represented in the new compiler, so this compiler is used to generate the "real" compiler for target machines.
To bootstrap, we use the quick and dirty compiler to compile the new compiler, and then recompile the new compiler with itself to generate an efficient version.
With bootstrapping, improvements to the source code can be bootstrapped by applying the 2-step process. Porting the compiler to a new host computer only requires changes to the backend of the compiler, so the new compiler becomes the "quick and dirty" compiler for new versions of the language.
If we use the main compiler for porting, this provides a mechanism to quickly generate new compilers for all target machines, and minimises the need to maintain/debug multiple compilers.
Lexical Analysis:
Lexical analysis is the first phase of a compiler. It takes the modified source code from language preprocessors that are written in the form of sentences. The lexical analyzer breaks these syntaxes into a series of tokens, by removing any whitespace or comments in the source code.
If the lexical analyzer finds a token invalid, it generates an error. The lexical analyzer works closely with the syntax analyzer. It reads character streams from the source code, checks for legal tokens, and passes the data to the syntax analyzer when it demands.
Tokens
Lexemes are said to be a sequence of characters (alphanumeric) in a token. There are some predefined rules for every lexeme to be identified as a valid token. These rules are defined by grammar rules, by means of a pattern. A pattern explains what can be a token, and these patterns are defined by means of regular expressions.
In programming language, keywords, constants, identifiers, strings, numbers, operators and punctuations symbols can be considered as tokens.
For example, in C language, the variable declaration line
int value = 100;
contains the tokens:
int (keyword), value (identifier), = (operator), 100 (constant) and ; (symbol).
Specifications of Tokens
Let us understand how the language theory undertakes the following terms:
Alphabets
Any finite set of symbols {0,1} is a set of binary alphabets, {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} is a set of Hexadecimal alphabets, {a-z, A-Z} is a set of English language alphabets.
Strings
Any finite sequence of alphabets is called a string. Length of the string is the total number of occurrence of alphabets, e.g., the length of the string tutorialspoint is 14 and is denoted by |tutorialspoint| = 14. A string having no alphabets, i.e. a string of zero length is known as an empty string and is denoted by e (epsilon).
Special Symbols
A typical high-level language contains the following symbols:-
Language
A language is considered as a finite set of strings over some finite set of alphabets. Computer languages are considered as finite sets, and mathematically set operations can be performed on them. Finite languages can be described by means of regular expressions.
Longest Match Rule
When the lexical analyzer read the source-code, it scans the code letter by letter; and when it encounters a whitespace, operator symbol, or special symbols, it decides that a word is completed.
For example:
int intvalue;
While scanning both lexemes till ‘int’, the lexical analyzer cannot determine whether it is a keyword int or the initials of identifier int value.
The Longest Match Rule states that the lexeme scanned should be determined based on the longest match among all the tokens available.
The lexical analyzer also follows rule priority where a reserved word, e.g., a keyword, of a language is given priority over user input. That is, if the lexical analyzer finds a lexeme that matches with any existing reserved word, it should generate an error.
Regular Expressions
The lexical analyzer needs to scan and identify only a finite set of valid string/token/lexeme that belongs to the language in hand. It searches for the pattern defined by the language rules.
Regular expressions have the capability to express finite languages by defining a pattern for finite strings of symbols. The grammar defined by regular expressions is known as regular grammar. The language defined by regular grammar is known as regular language.
Regular expression is an important notation for specifying patterns. Each pattern matches a set of strings, so regular expressions serve as names for a set of strings. Programming language tokens can be described by regular languages. The specification of regular expressions is an example of a recursive definition. Regular languages are easy to understand and have efficient implementation.
There are a number of algebraic laws that are obeyed by regular expressions, which can be used to manipulate regular expressions into equivalent forms.
Operations
The various operations on languages are:
Notations
If r and s are regular expressions denoting the languages L(r) and L(s), then
Precedence and Associatively
Representing valid tokens of a language in regular expression
If x is a regular expression, then:
Representing occurrence of symbols using regular expressions
letter = [a – z] or [A – Z]
digit = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 or [0-9]
sign = [ + | - ]
Representing language tokens using regular expressions
Decimal = (sign)?(digit)+
Identifier = (letter)(letter | digit)*
The only problem left with the lexical analyzer is how to verify the validity of a regular expression used in specifying the patterns of keywords of a language. A well-accepted solution is to use finite automata for verification.
A compiler translates the code written in one language to some other language without changing the meaning of the program. It is also expected that a compiler should make the target code efficient and optimized in terms of time and space. Compiler design principles provide an in-depth view of translation and optimization process. Compiler design covers basic translation mechanism and error detection & recovery. It includes lexical, syntax, and semantic analysis as front end, and code generation and optimization as back-end.
Phases of Compiler
The compilation process is a sequence of various phases. Each phase takes input from its previous stage, has its own representation of source program, and feeds its output to the next phase of the compiler. Let us understand the phases of a compiler. Please refer the below fig. 1
Lexical Analysis
The first phase of scanner works as a text scanner. This phase scans the source code as a stream of characters and converts it into meaningful lexemes. Lexical analyzer represents these lexemes in the form of tokens as:
<token-name, attribute-value>
Syntax Analysis
The next phase is called the syntax analysis or parsing. It takes the token produced by lexical analysis as input and generates a parse tree (or syntax tree). In this phase, token arrangements are checked against the source code grammar, i.e. the parser checks if the expression made by the tokens is syntactically correct.
Semantic Analysis
Semantic analysis checks whether the parse tree constructed follows the rules of language. For example, assignment of values is between compatible data types, and adding string to an integer. Also, the semantic analyzer keeps track of identifiers, their types and expressions; whether identifiers are declared before use or not etc. The semantic analyzer produces an annotated syntax tree as an output.
Intermediate Code Generation
After semantic analysis the compiler generates an intermediate code of the source code for the target machine. It represents a program for some abstract machine. It is in between the high-level language and the machine language. This intermediate code should be generated in such a way that it makes it easier to be translated into the target machine code.
Code Optimization
The next phase does code optimization of the intermediate code. Optimization can be assumed as something that removes unnecessary code lines, and arranges the sequence of statements in order to speed up the program execution without wasting resources (CPU, memory).
Code Generation
In this phase, the code generator takes the optimized representation of the intermediate code and maps it to the target machine language. The code generator translates the intermediate code into a sequence of (generally) re-locatable machine code. Sequence of instructions of machine code performs the task as the intermediate code would do.
Symbol Table
It is a data-structure maintained throughout all the phases of a compiler. All the identifier's names along with their types are stored here. The symbol table makes it easier for the compiler to quickly search the identifier record and retrieve it. The symbol table is also used for scope management.
Pass and Phases of translation:
- Compilation of a program proceeds through a fixed series of phases
- Each phase use an (intermediate) form of the program produced by an earlier phase
- Subsequent phases operate on lower-level code representations
- Each phase may consist of a number of passes over the program representation
- Pascal, FORTRAN, C languages designed for one-pass compilation, which explains the need for function prototypes
- Single-pass compilers need less memory to operate
- Java and ADA are multi-pass
- In logical terms a compiler is thought of as consisting of stages and phases
- Physically it is made up of passes
- The compiler has one pass for each time the source code, or a representation of
- it, is read
- Many compilers have just a single pass so that the complete compilation
- process is performed while the code is read once
- The various phases described will therefore be executed in parallel
- Earlier compilers had a large number of passes, typically due to the limited
- memory space available
- Modern compilers are single pass since memory space is not usually a problem
Bootstrapping
The idea behind bootstrapping is to write a compiler for a language in a possibly older version or a restricted subset of the language. A "quick and dirty" compiler is then written for that language that runs on some machine, but in a restricted subset or older version.
This new version of the compiler incorporates the latest features of the language and generates highly efficient code, and all changes to the language are represented in the new compiler, so this compiler is used to generate the "real" compiler for target machines.
To bootstrap, we use the quick and dirty compiler to compile the new compiler, and then recompile the new compiler with itself to generate an efficient version.
With bootstrapping, improvements to the source code can be bootstrapped by applying the 2-step process. Porting the compiler to a new host computer only requires changes to the backend of the compiler, so the new compiler becomes the "quick and dirty" compiler for new versions of the language.
If we use the main compiler for porting, this provides a mechanism to quickly generate new compilers for all target machines, and minimises the need to maintain/debug multiple compilers.
Lexical Analysis:
Lexical analysis is the first phase of a compiler. It takes the modified source code from language preprocessors that are written in the form of sentences. The lexical analyzer breaks these syntaxes into a series of tokens, by removing any whitespace or comments in the source code.
If the lexical analyzer finds a token invalid, it generates an error. The lexical analyzer works closely with the syntax analyzer. It reads character streams from the source code, checks for legal tokens, and passes the data to the syntax analyzer when it demands.
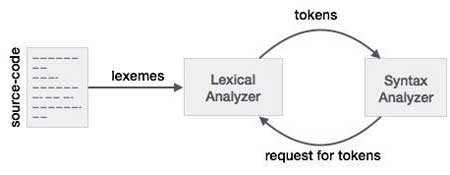
Tokens
Lexemes are said to be a sequence of characters (alphanumeric) in a token. There are some predefined rules for every lexeme to be identified as a valid token. These rules are defined by grammar rules, by means of a pattern. A pattern explains what can be a token, and these patterns are defined by means of regular expressions.
In programming language, keywords, constants, identifiers, strings, numbers, operators and punctuations symbols can be considered as tokens.
For example, in C language, the variable declaration line
int value = 100;
contains the tokens:
int (keyword), value (identifier), = (operator), 100 (constant) and ; (symbol).
Specifications of Tokens
Let us understand how the language theory undertakes the following terms:
Alphabets
Any finite set of symbols {0,1} is a set of binary alphabets, {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} is a set of Hexadecimal alphabets, {a-z, A-Z} is a set of English language alphabets.
Strings
Any finite sequence of alphabets is called a string. Length of the string is the total number of occurrence of alphabets, e.g., the length of the string tutorialspoint is 14 and is denoted by |tutorialspoint| = 14. A string having no alphabets, i.e. a string of zero length is known as an empty string and is denoted by e (epsilon).
Special Symbols
A typical high-level language contains the following symbols:-
| Arithmetic Symbols | Addition(+), Subtraction(-), Modulo(%), Multiplication(*), Division(/) |
| Punctuation | Comma(,), Semicolon(;), Dot(.), Arrow(->) |
| Assignment | = |
| Special Assignment | +=, /=, *=, -= |
| Comparison | ==, !=, <, <=, >, >= |
| Preprocessor | # |
| Location Specifier | & |
| Logical | &, &&, |, ||, ! |
| Shift Operator | >>, >>>, <<, <<< |
Language
A language is considered as a finite set of strings over some finite set of alphabets. Computer languages are considered as finite sets, and mathematically set operations can be performed on them. Finite languages can be described by means of regular expressions.
Longest Match Rule
When the lexical analyzer read the source-code, it scans the code letter by letter; and when it encounters a whitespace, operator symbol, or special symbols, it decides that a word is completed.
For example:
int intvalue;
While scanning both lexemes till ‘int’, the lexical analyzer cannot determine whether it is a keyword int or the initials of identifier int value.
The Longest Match Rule states that the lexeme scanned should be determined based on the longest match among all the tokens available.
The lexical analyzer also follows rule priority where a reserved word, e.g., a keyword, of a language is given priority over user input. That is, if the lexical analyzer finds a lexeme that matches with any existing reserved word, it should generate an error.
Regular Expressions
The lexical analyzer needs to scan and identify only a finite set of valid string/token/lexeme that belongs to the language in hand. It searches for the pattern defined by the language rules.
Regular expressions have the capability to express finite languages by defining a pattern for finite strings of symbols. The grammar defined by regular expressions is known as regular grammar. The language defined by regular grammar is known as regular language.
Regular expression is an important notation for specifying patterns. Each pattern matches a set of strings, so regular expressions serve as names for a set of strings. Programming language tokens can be described by regular languages. The specification of regular expressions is an example of a recursive definition. Regular languages are easy to understand and have efficient implementation.
There are a number of algebraic laws that are obeyed by regular expressions, which can be used to manipulate regular expressions into equivalent forms.
Operations
The various operations on languages are:
- Union of two languages L and M is written as
L U M = {s | s is in L or s is in M}
- Concatenation of two languages L and M is written as
LM = {st | s is in L and t is in M}
- The Kleene Closure of a language L is written as
L* = Zero or more occurrence of language L.
Notations
If r and s are regular expressions denoting the languages L(r) and L(s), then
- Union : (r)|(s) is a regular expression denoting L(r) U L(s)
- Concatenation : (r)(s) is a regular expression denoting L(r)L(s)
- Kleene closure : (r)* is a regular expression denoting (L(r))*
- (r) is a regular expression denoting L(r)
Precedence and Associatively
- *, concatenation (.), and | (pipe sign) are left associative
- * has the highest precedence
- Concatenation (.) has the second highest precedence.
- | (pipe sign) has the lowest precedence of all.
Representing valid tokens of a language in regular expression
If x is a regular expression, then:
- x* means zero or more occurrence of x.
i.e., it can generate { e, x, xx, xxx, xxxx, … }
- x+ means one or more occurrence of x.
i.e., it can generate { x, xx, xxx, xxxx … } or x.x*
- x? means at most one occurrence of x
i.e., it can generate either {x} or {e}.
[a-z] is all lower-case alphabets of English language.
[A-Z] is all upper-case alphabets of English language.
[0-9] is all natural digits used in mathematics.
Representing occurrence of symbols using regular expressions
letter = [a – z] or [A – Z]
digit = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 or [0-9]
sign = [ + | - ]
Representing language tokens using regular expressions
Decimal = (sign)?(digit)+
Identifier = (letter)(letter | digit)*
The only problem left with the lexical analyzer is how to verify the validity of a regular expression used in specifying the patterns of keywords of a language. A well-accepted solution is to use finite automata for verification.
Published date : 06 Feb 2016 12:38PM



